微服务架构下的数据治理 构建高效、可靠的数据处理服务

随着企业数字化转型的深入,微服务架构因其灵活性、可扩展性和敏捷性而成为主流。微服务带来的分布式数据管理挑战也日益凸显,数据治理——尤其是在数据处理服务层面——成为确保系统健康与业务价值的关键。本文将探讨微服务架构下数据治理的核心挑战,并阐述如何构建与治理高效、可靠的数据处理服务。
一、 微服务数据治理的核心挑战
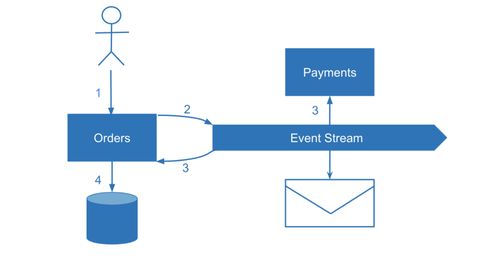
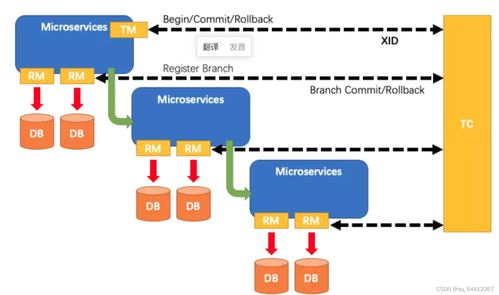
- 数据孤岛与一致性难题:每个微服务拥有独立的数据库(遵循“数据库私有化”原则),这虽然提升了服务自治性,但也导致了数据的物理分散。跨服务的数据一致性(如订单服务与库存服务)无法通过传统的数据库事务保证,需要引入分布式事务(如Saga模式)或最终一致性方案,治理复杂度剧增。
- 数据定义与标准不统一:不同团队开发的微服务可能对同一业务实体(如“客户”)有不同的数据模型和定义,导致数据口径混乱,影响跨域数据分析与决策。
- 数据血缘与溯源困难:数据在多个服务间流转、加工,其完整的生命周期和转换路径(数据血缘)难以追踪。当数据出现质量问题时,定位根源和影响范围成为巨大挑战。
- 数据处理服务的可靠性与可观测性:专门负责数据抽取、转换、加载(ETL)、实时计算或数据清洗的微服务(即数据处理服务),其运行状态、性能指标、错误日志需要被有效监控和治理,否则可能成为数据流水线上的薄弱环节。
二、 构建与治理数据处理服务的策略
- 确立统一的数据治理框架与组织:在架构层面,应设立企业级的数据治理委员会或虚拟团队,制定统一的数据标准、模型规范、质量规则和生命周期管理政策。为数据处理服务定义清晰的契约,包括输入/输出格式、SLA(服务等级协议)和错误处理机制。
- 实施API驱动的数据访问与集成:严格禁止服务间的直接数据库访问。所有跨服务数据交互必须通过定义良好的API(如RESTful API、gRPC或异步消息)进行。数据处理服务应作为数据的“加工中心”和“提供者”,通过API对外提供清洗、聚合后的高质量数据。这封装了数据复杂性,并便于监控和版本管理。
- 强化数据契约与Schema管理:在服务间(特别是生产者与消费者之间)建立明确的数据契约。使用如Avro、Protobuf等Schema Registry工具集中管理数据结构,确保上下游服务对数据格式的理解一致,并能平滑处理Schema演化。
- 构建可观测的数据处理流水线:为关键的数据处理服务集成全面的可观测性工具链:
- 日志集中化:聚合所有处理日志,便于调试和审计。
- 指标监控:监控吞吐量、延迟、错误率等关键指标,并设置警报。
- 分布式追踪:集成如Jaeger、Zipkin等工具,追踪一个数据请求跨越多个服务的完整路径,清晰展现数据血缘。
- 保障数据质量与可靠性:在数据处理服务内部嵌入质量检查点:
- 输入验证:对接收的数据进行格式、完整性、有效性校验。
- 处理过程监控:实现数据处理的幂等性、重试和死信队列机制,防止数据丢失或重复。
- 输出质量评估:对处理后的数据应用预定义的质量规则(如准确性、及时性、一致性),并可自动触发修复流程或告警。
- 拥抱事件驱动架构:利用消息中间件(如Kafka、Pulsar)构建事件驱动的数据处理流。数据处理服务作为事件消费者或生产者,实现数据的实时或近实时流动与加工。这天然支持解耦、异步处理和流量削峰,同时消息队列自带的数据持久化与重放能力为数据溯源提供了基础。
- 实现安全与合规的数据处理:在数据处理服务中集成数据脱敏、加密、访问控制(基于角色的访问控制,RBAC)和审计日志功能,确保对敏感数据的处理符合GDPR等法规要求。
三、
在微服务架构下,数据治理并非一个独立的、事后的环节,而应作为一项贯穿于服务设计、开发、运维全过程的系统工程。数据处理服务作为数据价值链的核心载体,其治理水平直接决定了数据的可用性、可信度和价值。通过建立统一的治理框架、API化集成、强化可观测性、嵌入质量保障并采用事件驱动模式,企业可以构建出既敏捷又稳健的数据处理能力,从而在分布式环境中将数据真正转化为驱动业务创新的核心资产。
如若转载,请注明出处:http://www.rikmuixpx.com/product/47.html
更新时间:2026-04-17 05:55:08