智慧工厂大数据平台数据处理服务建设方案
一、建设背景与目标
随着工业4.0时代的到来,智慧工厂已成为制造业转型升级的重要方向。大数据平台作为智慧工厂的核心基础设施,其数据处理服务能力直接影响工厂的智能化水平和运营效率。本方案旨在构建一个高效、稳定、可扩展的数据处理服务体系,为智慧工厂提供全方位的数据支撑。
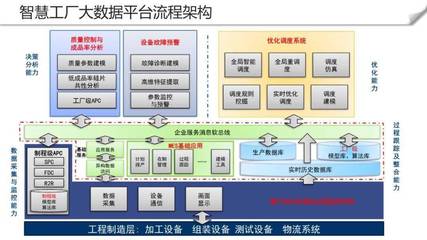
二、数据处理服务架构设计
1. 数据采集层
- 设备数据采集:通过工业网关、传感器等设备实时采集生产设备运行数据
- 业务系统集成:对接ERP、MES、SCADA等系统,获取业务管理数据
- 外部数据接入:整合供应链、市场环境等外部数据源
2. 数据存储层
- 实时数据库:存储设备实时监控数据,支持毫秒级响应
- 数据湖:构建企业级数据湖,存储结构化与非结构化数据
- 数据仓库:建立主题式数据仓库,支撑业务分析需求
3. 数据处理层
- 流式处理:采用Flink、Spark Streaming等技术实现实时数据处理
- 批处理:构建ETL/ELT数据处理流水线,实现批量数据加工
- 数据融合:整合多源异构数据,形成统一数据视图
4. 数据服务层
- 数据API服务:提供标准化数据接口,支持业务系统调用
- 数据可视化:开发数据看板、报表等可视化工具
- 数据分析:内置机器学习算法,支持预测性维护等场景
三、核心数据处理服务功能
1. 实时数据处理服务
- 设备状态实时监控:毫秒级响应设备异常状态
- 生产过程实时分析:实时计算生产指标,优化生产调度
- 质量实时控制:实时检测产品质量,及时预警
2. 批处理数据服务
- 数据清洗与标准化:自动识别并处理数据质量问题
- 数据关联与整合:建立设备、工艺、质量等数据的关联关系
- 数据归档与备份:建立完善的数据生命周期管理体系
3. 智能分析服务
- 预测性维护:基于设备运行数据预测故障风险
- 工艺优化:通过数据分析发现工艺改进空间
- 能源管理:实时监控能耗,优化能源使用效率
四、技术实现方案
1. 技术选型
- 数据处理框架:Apache Flink、Apache Spark
- 消息队列:Kafka、Pulsar
- 存储系统:HDFS、HBase、ClickHouse
- 容器化部署:Kubernetes、Docker
2. 数据处理流程
- 数据接入:通过数据采集网关接入各类数据源
- 数据解析:解析数据格式,进行初步清洗
- 数据校验:验证数据完整性和准确性
- 数据转换:标准化数据格式,统一数据模型
- 数据加载:加载到目标存储系统
- 数据服务:通过API或可视化方式提供服务
3. 性能保障措施
- 分布式架构设计,支持水平扩展
- 负载均衡机制,确保系统稳定运行
- 数据压缩与索引优化,提升查询效率
- 缓存机制设计,减少重复计算
五、实施规划与效益评估
1. 分阶段实施计划
- 第一阶段(3个月):基础平台搭建,核心数据采集
- 第二阶段(6个月):数据处理服务完善,关键应用开发
- 第三阶段(12个月):全面推广应用,持续优化提升
2. 预期效益
- 生产效率提升:预计提升15%-20%
- 故障率降低:预期降低设备故障率30%
- 质量控制:产品质量一致性提升25%
- 成本节约:预计降低维护成本20%
六、保障措施
- 安全机制:建立完善的数据安全防护体系
- 运维监控:实现7×24小时系统监控与告警
- 技术支持:组建专业的技术支持团队
- 培训体系:建立全员数据素养提升计划
本方案通过构建全面的数据处理服务体系,将为智慧工厂提供强大的数据支撑能力,助力企业实现数字化、智能化转型,在激烈的市场竞争中赢得先机。
如若转载,请注明出处:http://www.rikmuixpx.com/product/4.html
更新时间:2026-02-25 09:12:14